")
")
")
Di seguito vi spieghiamo i "retroscena" dei set di caratteri, i problemi che possono manifestarsi in questo contesto e le relative soluzioni.
Mojibake: database e set di caratteri
È da tempo passata l’epoca in cui i computer erano dispositivi ingombranti e costosi. Oggi quasi tutti possono utilizzare in ogni lingua queste macchine che all’origine erano prerogativa di una élite ristretta e disponibili solo in inglese. Ma l’infinità di lingue, alfabeti e pertanto caratteri diversi rispetto allo standard originario inglese continuano a presentare problemi.
Questo articolo spiega come il database MySQL affronta tale problematica e come è possibile risolvere le fastidiose complicazioni dovute a dieresi e caratteri speciali.
Nascita e strutturazione dei set di caratteri
Inizialmente tutto era US-ASCII. O quasi. Dagli anni ’60 la più piccola unità di memorizzazione utilizzata dai computer corrisponde a 8 bit (8 bit = 1 byte). 8 bit corrispondono ai numeri da 0 a 255. Per consentire ai computer di raffigurare del testo, a queste cifre sono stati assegnati dei caratteri di testo. Per garantire la compatibilità tra i sistemi allora utilizzati, nel 1969 è stato standardizzato il formato ASCII: alle prime 7 combinazioni di bit sono stati assegnati dei caratteri: era nato il primo "charset" ("character-set", in inglese set di caratteri). Così ad esempio il numero 65 corrisponde alla lettera "A".
Affinché rimanesse spazio per nuovi sviluppi e nuovi caratteri (ad es. il carattere dell’euro), solo la metà dei 256 caratteri è stata definita in modo fisso come US-ASCII. Tali segni contenevano tutti i caratteri di scrittura inglesi. Pertanto i simboli, le dieresi e i caratteri speciali delle altre lingue dovevano rientrare nella seconda metà dei 256 caratteri. Dal momento che però nel mondo esistono ben più di 256 caratteri testuali (si pensi ad es. alla scrittura cinese), ad oggi esistono molte diverse estensioni per tutte le lingue possibili. Il set di caratteri più importante per l’Europa è costituito dalla famiglia ISO-8859. Solo all’inizio degli anni ’90 con Unicode è stata elaborata una strategia in grado di raffigurare tutti i set di caratteri. Tuttavia finora Unicode non è ancora stato impiegato in modo sistematico in tutti i sistemi operativi e in tutte le applicazioni.
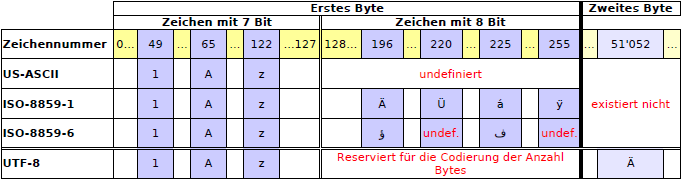
Figura 1: Tabella dei caratteri con esempi dei set di caratteri ISO-8859-1, ISO-8859-6 e UTF-8.
I set di caratteri più diffusi
Nei paragrafi seguenti accenneremo brevemente ai set di caratteri più in uso per le lingue dell’Europa occidentale.
ISO-8859-1 o latin-1
Questo set di caratteri si avvale di un intervallo fisso di 8 bit per codificare i caratteri. I caratteri codificabili con i primi 7 bit (0–127) corrispondono al set di caratteri US-ASCII. La seconda metà (128–255) contiene i caratteri diffusi per l’Europa occidentale, l’America, l’Australia e parti dell’Africa. Il simbolo dell’Euro non è compreso.
ISO-8859-15 o latin-9
Questo set di caratteri si avvale di un intervallo fisso di 8 bit per codificare i caratteri. I caratteri codificabili con i primi 7 bit (0–127) corrispondono al set di caratteri US-ASCII. La seconda metà (128–255) contiene i caratteri diffusi per l’Europa occidentale compreso il simbolo dell’Euro, con supporto completo per francese, inglese (US), Australia e parte dell’Africa.
UTF-8
Questo set di caratteri è stato sviluppato per poter utilizzare un set di caratteri unitario per tutte le lingue. Pertanto la codifica è un po’ più complicata.
UTF-8 utilizza un intervallo variabile per il salvataggio dei caratteri. US-ASCII è compreso nei primi 7 bit. Pertanto i caratteri US-ASCII possono essere salvati in un byte. Tutti gli altri caratteri come le dieresi richiedono 2 o più byte (contrariamente a quanto avviene con ISO-8859-x che richiede soltanto 1 byte).
UTF-8 supporta quasi tutti gli alfabeti utilizzati nel mondo.
Problemi
Con questo set di caratteri di base US-ASCII e le varie estensioni specifiche per ciascuna lingua è ora possibile raffigurare gran parte dei caratteri esistenti, a condizione che si definisca in quale set di caratteri è stato scritto il testo. In assenza di questa informazione il computer non può decidere se il carattere numero 196 deve raffigurare una "Ä" secondo ISO-8859-1 o un "?" secondo ISO-8859-6. Gli utenti di MS-DOS conosceranno anche il problema delle cornici di testo delle applicazioni, visualizzate come "mojibake" rettangolare di lettere anziché come cornice. Il problema riguarda anche Unicode: se non è chiaro che un testo è scritto con Unicode, la "Ä" verrà trasformato in un geroglifico formato da due segni strani (dal momento che Unicode salva tutti i caratteri non US-ASCII in 2 o più byte).
Testo nei database
Anche i database possono memorizzare dei testi. In caso di siti web basati su database si tratta del loro compito principale. Per risolvere il problema del mojibake i database offrono la possibilità di definire set di caratteri per ciascuna casella di testo. In questo modo durante la scrittura o più tardi durante la lettura verranno visualizzati i caratteri giusti. Lo dimostra il seguente dump:
/*!40101 SET NAMES utf8 */;
CREATE TABLE `user` (
`Id` INT NOT NULL AUTO_INCREMENT,
`User` VARCHAR(255) CHARSET=latin1 NOT NULL default ,
`Occupation` VARCHAR(255) NOT NULL default ,
PRIMARY KEY (`Id`,`User`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='Users';Questo semplice database salva in una tabella tre campi:
| Nome campo | Tipo | Set di caratteri |
|---|---|---|
| Id | INT (numero) | nessuno (numero) |
| User | VARCHAR (Text) | latin-1 (specifico per questo campo) |
| Occupation | VARCHAR (Text) | (standard UTF-8 per questa tabella) |
- Di default questa tabella utilizza il set di caratteri UTF-8. (DEFAULT CHARSET=utf8 sull’ultima riga.)
- Tuttavia il campo "User" viene salvato come latin-1. (CHARSET=latin1 sulla 4a riga).
- L’intero dump è in UTF-8. (definito dall’istruzione "SET NAMES utf8" nel commento, 1a riga).
- Il confronto definisce la sequenza di ordinamento all’interno dell’alfabeto e non il set di caratteri, come spesso si crede. (COLLATE=utf8_bin nell’ultima riga.)
Pertanto per questo dump il campo "Utente" è stato convertito dalla rappresentazione interna al database in latin-1 a UTF-8. latin-1 è completamente rappresentabile in UTF-8. Al momento della lettura del dump, il campo "Utente" viene riconvertito da UTF-8 al set di caratteri originario (latin-1).
Accesso al testo nei database: la libreria del database
Dunque il testo contenuto nei database può essere salvato con un set di caratteri definito in modo fisso. L’intermediario tra il database e l’applicazione è costituito da una libreria di programmi, chiamata anche "libreria client" o semplicemente "libreria", che disciplina lo scambio di dati.
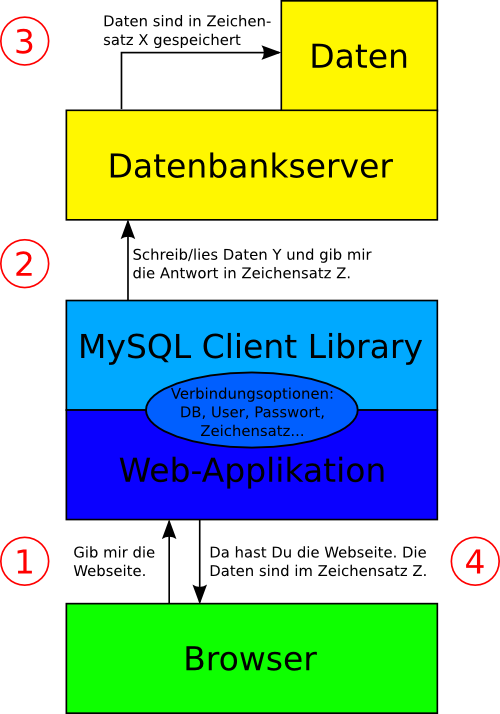
Figura 2: svolgimento schematico e interazione dei componenti di un sito web con DB.
Questa libreria programmi può trasmettere i dati 1:1 come sono salvati nel database oppure convertirli da un set di caratteri a un altro (ad es. da latin-1 a UTF-8). Se il programma che usa la libreria non definisce qual è il comportamento richiesto, questo sarà scelto arbitrariamente. Se il set di caratteri con cui devono essere scambiati i dati non è definito non si garantisce che i testi vengano raffigurati o memorizzati correttamente.
Il set di caratteri utilizzato per il collegamento viene stabilito con la seguente istruzione in MySQL:
/*!40101 SET NAMES utf8 */;
Nel vostro codice PHP potrebbe apparire come segue:
$DB->query("SET NAMES 'utf8'");
oppure:
mysql_query("SET NAMES 'utf8'",$connection);
L’applicazione web
Se finora l’intero svolgimento dal database attraverso la "libreria" è avvenuto con il set di caratteri corretto, sta all’applicazione web trasmettere al browser i dati con il set corretto. Il set di caratteri utilizzato nell’HTML generato deve essere dichiarato tramite meta-tag nell’intestazione HTML o nell’intestazione HTTP al momento della trasmissione dei dati. Anche in questo caso una dichiarazione sbagliata provoca il mojibake con tutti i caratteri non US-ASCII come le dieresi.
Definizione del set di caratteri mediante l’intestazione HTTP
Di solito il set di caratteri viene indicato nell’intestazione HTTP al momento della trasmissione dei dati. Con la seguente intestazione HTTP viene definito UTF-8 come set di caratteri:
Content-Type: text/html; charset=utf-8
Nella vostra applicazione PHP il codice PHP per definirlo potrebbe apparire come segue:
header('Content-Type: text/html; charset=utf-8');
Definire il set di caratteri in HTML
Il set di caratteri può essere definito anche tramite metatag http-eqiv direttamente in HTML. Il codice HTML appare più o meno come segue:
<head>
<meta http-equiv="content-type" content="text/html; charset=ISO-8859-15">
</head>Definizione del set dei caratteri dei moduli
Al contrario, quando si trasmette il testo nei moduli alla vostra applicazione deve essere definito chiaramente il set di dei caratteri accettato. In caso contrario il testo inviato dal browser può avere un set di caratteri qualsiasi. Se la vostra applicazione web non effettua un’analisi accurata in un caso simile, ed eventualmente una conversione, il fatto che la sequenza di caratteri nel database venga effettivamente scritta nel set di caratteri definito nel database è una questione di sola fortuna.
Esempio di modulo con set di caratteri definito con precisione per le caselle di testo:
<form action="action.php" accept-charset="ISO-8859-15">
Name: <input type="text" name="name" />
Nachname: <input type="text" name="nachname" />
<input type="submit" value="Senden!" />
</form>Casi di errore
Esistono quasi infinite varianti causa di mojibake. Tuttavia possono essere riassunte nelle tre categorie principali seguenti.
Il set di caratteri dichiarato non coincide con quello effettivo del database
Tali dati pervengono nel database ad esempio quando un browser trasmette i dati della casella di testo di un modulo come UTF-8 perché manca l’istruzione accept-charset="ISO-8859-15" e l’applicazione che verifica i dati scrive in un campo del database dichiarato come latin-1 senza controlli. L’esito è corretto fintantoché il set di caratteri del collegamento con il database rimane invariato. Se questo non è definito, in caso di cambiamento del provider, di versione del database o di aggiornamento del server potrebbero manifestarsi problemi improvvisi.
I dati vengono convertiti due volte o in modo sbagliato
I dati di testo di un modulo vengono trasmessi nel set di caratteri UTF-8 (come definito via HTML) e devono essere scritti in un campo del database dichiarato come UTF-8. Tuttavia nel collegamento con il database non è stato definito alcun set di caratteri con SET NAMES, oppure ne è stato definito uno errato. Pertanto i caratteri UTF-8 vengono nuovamente convertiti da un altro set di caratteri in UTF-8. Nel caso peggiore tutti i caratteri non US-ASCII vengono distrutti.
Questo può avvenire anche in caso di emissione di testi dal database: in un database dichiarato come latin-1 sono stati salvati per sbaglio dei testi UTF-8. Ad esempio se il collegamento con il database è configurato in modo che tutti i testi vengano forniti in UTF-8, la libreria cercherà di riconvertire in UTF-8 il testo in presunto latin-1. Anche in questo caso il risultato è il mojibake.
Il set di caratteri per la visualizzazione dei dati nel browser viene impostato in modo scorretto o non viene impostato affatto
L'errore più facile da correggere. I dati vengono memorizzati e visualizzati con un set di caratteri definito in modo coerente, ma il set di caratteri utilizzato non è definito nell'intestazione HTTP o HTML. In questo caso, la maggior parte dei browser cerca di indovinare il charset con diversi gradi di successo Poiché i dati sono memorizzati in modo coerente nell'applicazione e nel database, questo problema può essere risolto con una semplice dichiarazione php o HTML. (vedi sopra)
Riepilogo: Best Practice
Riassumendo, possiamo elencare le seguenti linee guida per evitare problemi legati al set di caratteri nell’uso dei database.
- Per ogni casella di testo, tabella o database dichiarate il set di caratteri! Non devono esserci caselle di testo senza definizione del set di caratteri.
- Per ogni collegamento MySQL dichiarate il set di caratteri con SET NAMES.
- Dichiarate il set di caratteri delle vostre pagine via HTTP o nell’intestazione HTML.
- Per ogni modulo, dichiarate i set di caratteri accettati. Tuttavia sappiate che i browser possono comunque inviare dati con un set di caratteri errato.
- Controllate di aver indicato sempre un unico set di caratteri per SET NAMES, sia alla lettura sia alla creazione di un dump.
Risoluzione dei problemi: se si è già creato il mojibake
La situazione di partenza per tentare un recupero è costituita dall’analisi del problema: dovete sapere quali errori sono presenti nella vostra applicazione o nei dati del database. Se l’errore è presente solo in uno dei punti possibili, attenetevi alla sequenza riportata di seguito per trovare e risolvere il problema.
Il browser utilizza un set di caratteri sbagliato
Prima di tutto verificate che il vostro browser utilizzi il set di caratteri giusto. Per farlo la maggior parte dei browser consente di visualizzare e modificare manualmente il set di caratteri utilizzato. Il set di caratteri coincide con quello previsto? Di solito per i siti europei sono diffusi e adeguati i set di caratteri della famiglia ISO-8859, in particolare ISO-8859-1, ISO-8859-15 e UTF-8. Sito web Hostpoint raffigurato con un set di caratteri sbagliato: ISO-8859-1 (latin-1) anziché UTF-8.
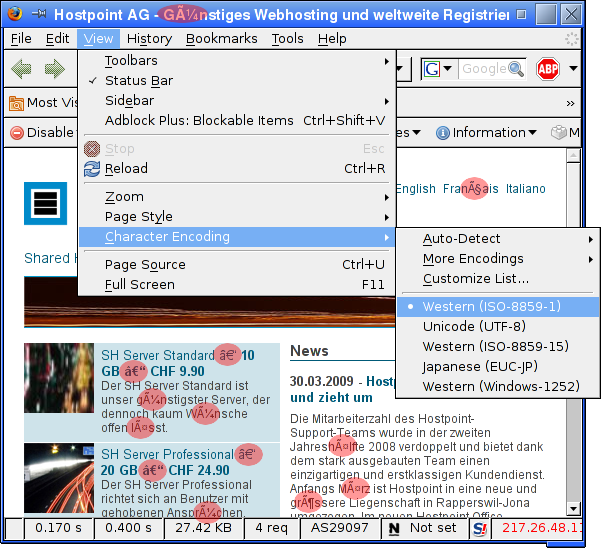
Figura 3: sito web Hostpoint raffigurato con un set di caratteri sbagliato: ISO-8859-1 (latin-1) anziché UTF-8.
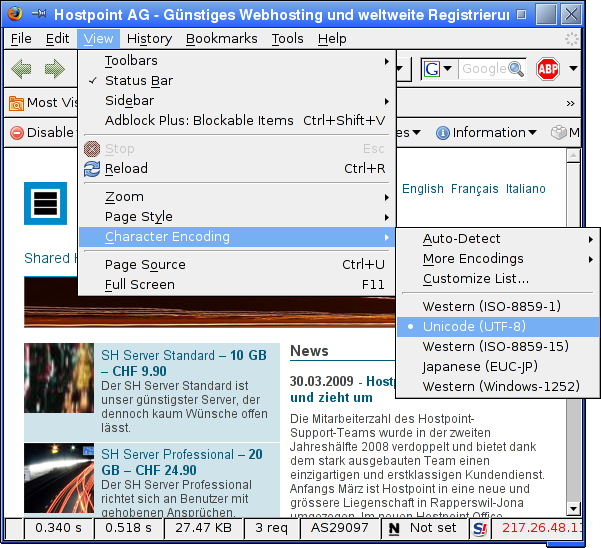
Figura 4: sito web Hostpoint raffigurato con un set di caratteri corretto: UTF-8
Se al posto delle dieresi vengono raffigurati caratteri simili a virgole o non viene raffigurato alcun carattere, probabilmente si verifica il caso contrario: il browser rappresenta i caratteri dei set ISO-8859 come UTF-8.
Soluzione: accertatevi di indicare il set di caratteri giusto nell’intestazione HTTP e nel codice HTML.
Per richieste di supporto la preghiamo di usare invece questo modulo.